Transformer Intepretion and Code
Attention is all your need
Attention is all your need这篇谷歌的transformer开山之作奠定了如今大热的GPT和机器视觉领域神经网络的基础架构。本文将在理解论文的基础上,结合其它材料,进一步深入了解具体代码实现(pytorch),并给出一个fine tune的实际应用例子。
Paper Introduction
Transformer是第一个提出只使用attention+residual connection+MLP架构的神经网络, 起初论文用这种架构去做序列到序列的文本翻译工作,相比RNN和CNN, transformer在大规模训练集上的表现更好,同时这个架构也提高了计算并行性和计算效率。那么为什么它会表现地更好? 初步的研究发现,原因有如下几点:
transformer在网络中引入了更少的inductive bias归纳偏置,所以有更好的泛化性,对于没有训练过的样本就有更好的表现;- 同时attention机制可以全局地计算出序列之间的相关性,相对CNN可以更好地理解上下文,而不是局限卷积窗口特征;
- 更少的网络深度减少了长距离传输梯度消失的问题,相对RNN就有更好的长输入表现;
- 当然
transformer引入残差连接也是性能提升的另一个因素,具体还有其他原因分析还待进一步研究。
Model Architecture
transformer使用了encoder-decoder编码器-解码器架构, 整体架构论文完美地画了出来。实现的代码如下:![]()
1 | import torch.nn as nn |
上图中编码器和解码器实际上是由6个一样的网络串行堆叠而成,它的大致架构如下图: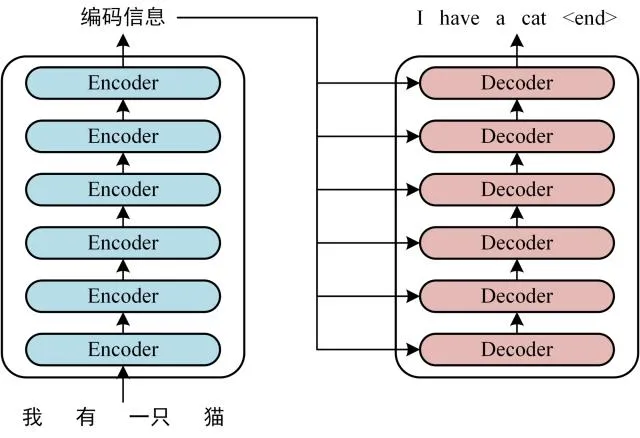
编码器输入
对于翻译序列的例子,在数据输入阶段经过了如下流程:
- 当输入句子X(x1,x2…xn), 模型先对其做
embedding,生成每个词对应的向量Z(z1,z2…zn). - 然后在Z后加入位置编码信息,位置信息可以用余弦来表示,随后加入编码器输入。正弦和余弦的公式是:
1 | import math |
编码器层
编码器由6个一样的网络串行组成,每个网络由一个多头注意力层和Feed forward前向反馈网络层组成。
1 | def clones(module, N): |
多头注意层
多头注意层是输入(K,V,Q)经过8个可学习的线性投影,再经过并行的自注意机制(点积计算),最后把结果相加并且投影缩放回来。这篇论文用的自注意力机制是scaled dot product即阶化的点积。整体自注意力层和多头层论文也很好地画了出来。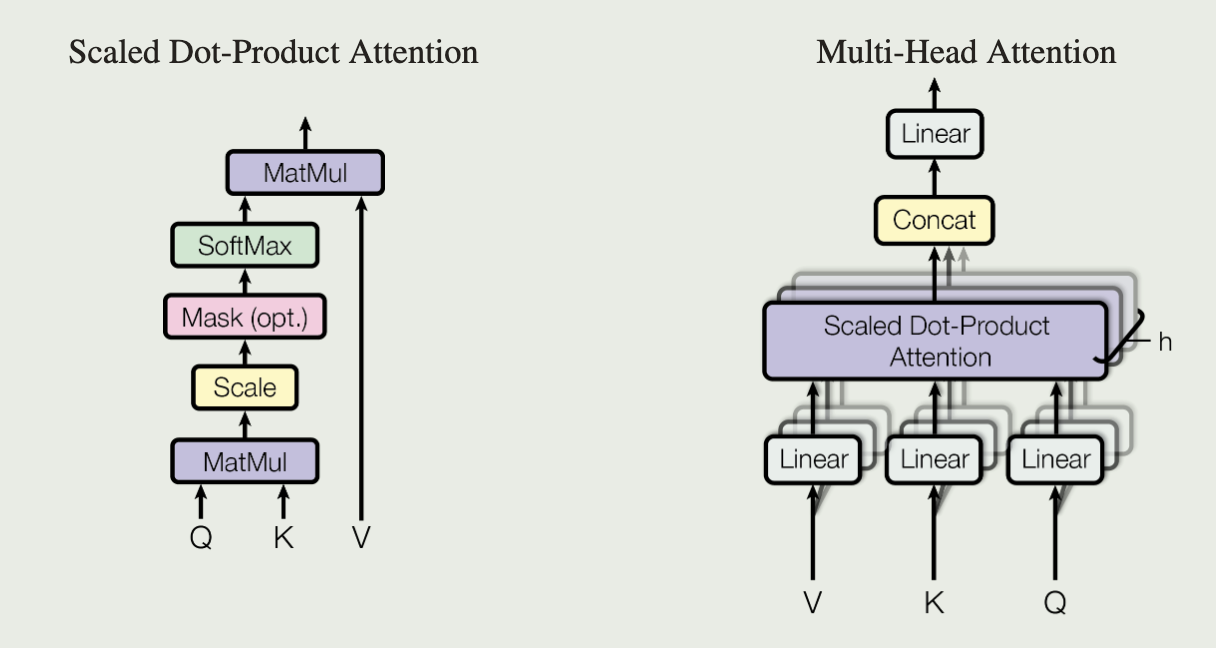
自注意计算的公式是:
1 | def attention(query, key, value, mask=None, dropout=None): |
多头注意力机制的公式是:
Where the projections are parameter matrices:
多头注意力代码如下:
1 | import copy |
前馈网络
前向反馈网络就是一个2层感知机MLP,经过一层ReLU然后再经过一层线性层, 公式如下:
1 | class PositionwiseFeedForward(nn.Module): |
LayerNorm
在每个子层输出还需要做layerNorm和残差连接. LayerNorm的大致公式如下图, LayerNorm主要是将样本值在特征维度上做归一化处理:
1 | class LayerNorm(nn.Module): |
残差连接
每个子层的输出将通过残差连接,然后再通过LayerNorm, 这里代码实现将先进行归一化然后再做dropout(cite)最后再进行残差连接, 目的是为了代码简单。
子层输出经过公式:
1 | class SublayerConnection(nn.Module): |
整个编码层代码如下:
1 | class EncoderLayer(nn.Module): |
解码器层
解码器层比编码器多了一个带mask的多头注意力层,同时编码器的输出也会是解码器的输入,另一个输入是编码器按位之前已经生成结果。
1 | class Decoder(nn.Module): |
整体模型
1 | def make_model( |
- Title: Transformer Intepretion and Code
- Author: Kopei
- Created at : 2023-04-02 17:12:16
- Updated at : 2023-12-06 18:12:00
- Link: https://kopei.github.io/2023/04/02/Transformer-Architecture-code/
- License: This work is licensed under CC BY-NC-SA 4.0.